Some Thoughts on Using Symbols In Programming Languages
In the Python-based pattern matching work described in Pattern Matching in Python I've used a variety Python-provided operator names to implement a pattern-matching sublanguage. For example:
-
"I ^ P" applies a pattern (P) to a source of input data (I).
-
"P1 & P2" matches P1 and then P2, and succeeds only if both do.
-
"P [n:m]" matches from "n" to "m" copies of the pattern P.
-
"P [n:]" matches "n" or more of P.
-
"P1 - P2" matches P2 so long as it doesn't also exactly match P2.
When I first publicly presented the implementation, one of the audience members, a bit tongue-in-cheek, described my use of these operator names as a "perversion" -- meaning a use other than that intended by the language designer, and not following conventional use. My response was:
-
I was stuck with the operators that Python provides, because one can't, in the current release of the language, define one's own additional operator names.
-
Kids learn the basic arithmetic operators in school, which sets their perception of what's "normal" vis-a-vis the use of arithmetic-like expressions.
One always has after-the-fact thoughts after an exchange like this. This paper is essentially the wish-I'd-saids on the use of operator names in programming languages in general, and in Python in particular.
There are essentially two constraints on the use of names in programming languages:
-
the severely limited set of readily available characters on the common keyboard, and
-
the precedents set by early programming languages.
But we aren't necessarily limited by these constraints. Historically we've been very flexible in the way we use available characters both for computer use and general language use. A bit of background might help in guiding us in the way we use available characters.
1. Traditional Programming Language Operator Names
There is nothing "natural" or "intrinsic" about most of the names and symbols currently used in programming languages. A number of the choices follow pre-computer mathematical precedents, most notably "+", "-", "=", "<" and ">" and the use of parentheses: "(" and ")". Some are close fits, like "/" for division and the composite "<=" and ">=" symbols.
Most uses of keyboard characters are early adaptations of their use for mathematical purposes. At the time they were adopted they were chosen on the basis of what's best given what we've got? Examples of inventions include:
-
"*" for multiplication -- in the absence of a suitable x-like multiplication symbol.
-
"_" for a "dash" in names -- to avoid confusion with the use of "-" for subtraction. Traditional printing fonts typically have distinct representations for hyphen, n-dash (short), m-dash (long) and minus sign (large and centered), but that's not available on our keyboards, so we've got to take care with how we use "-".
-
The use of "|" for a variety of purposes, including "or".
-
The use of ";" and other punctuation marks as "terminating" symbols, such as statement end.
-
The use of "[" and "]" for subscripting -- in the absence of subscripting.
-
The use of "**" for the power operator -- in the absence of superscripting.
Later adaptations include:
-
The use of "!" for the negation operator. In the early days of computer languages other choices were used. On IBM and other machines there was a "not" character (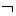 ), based on mathematical precedent. On some ASCII machines, "~" was the choice. And then came along the C programming language, which for some reason used "!" rather than "~", and the precedent was set.
), based on mathematical precedent. On some ASCII machines, "~" was the choice. And then came along the C programming language, which for some reason used "!" rather than "~", and the precedent was set.
-
The use of the circumflex accent, "^", for various purposes, including C's bit-wise exclusive-or operator.
-
The use of "==" for "is equal to" so that "=" could be used for the assignment operation. C made this change on the grounds that:
-
assignment is more common than comparison,
-
using "=" for assignment made assignments look more declarative, and
-
because of the clumsiness of using what was then common in Algol-family languages: ":=".
-
The use of "+" for string and list concatenation.
-
Just about any use of "\" you can think of.
All of these uses can be described as "perversions", but they are really just expedients -- you use what you've got.
2. An Aside On The Letter "A"
The letter "A" started out life about 3800 years ago, carved on rocks in central Egypt by Semitic-speaking workers or troops who had presumably seen hieroglyphics and needed something better suited to their own language and use. It was called "Ox", based on its appearance (turn it upside-down: 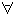 ), which is "‘alef" in the Semitic languages.
), which is "‘alef" in the Semitic languages.
As is common in Semitic languages, the word ‘alef consists of three consonants: a glottal way-back-in-the-mouth sound (represented here by "‘"), "l" and "f". The word was written as three consonants: the role of vowels and consonants is different in Semitic languages (like Arabic, Hebrew and Phoenician) from that in Indo-European languages (like English, Hindu and Greek). Writing the consonants suffices in Semitic languages. But Indo-European languages depend heavily on vowels to make semantic and grammatical distinctions between words, so the vowels need to be written down explicitly.
It's a common convention in all these languages that the first sound in the name of a letter is the sound of named letter. (Recite the alphabet, and you'll see it's more common than not for our letters.) In Semitic languages, ‘alef was and is the name of the glottal sound ("‘"), and "A" (or its analog) is the symbol for it. When, about 2800 years ago, the Phoenician alphabet was adapted for their own use by the Greeks, they needed to invent vowels. So they used the Phoenician letters that were also Greek sounds as-is. Then they took the remaining Phoenician letters -- all consonants -- and assigned them to Greek sounds that didn't appear in Phoenician. Some were used for Greek vowels, and others for Greek consonants. They also kept most of the Phoenician letter names, pronounced in a Greek way: the name ‘alef became "aleph", with the leading glottal consonant dropped. Aleph stayed the name of "A", but the sound changed to the first sound in aleph, as it is in most European languages.
This process of reassignment has continued up to the present day: the Chinese roman-based phonetic alphabet (pinyin) reassigns European language letters to Chinese language sounds.
(There's an excellent book outlining the history and use of the letters in our language by David Sacks: Language Visible -- Unraveling the Mystery of the Alphabet from A to Z.)
There are two trends to be observed in the history of "A" and the other letters:
-
We've been very conservative in which letters we use: we can look at an "A" from 3800 years ago and, with a bit of historical help, recognize it for what it is.
-
We've been very flexible in how we use the letters we have. The evidence for early uses of "A" may be literally carved in stone, but figuratively, the use we make of "A" is not carved in stone.
These trends parallel the use of keyboard characters in programming languages:
-
We're conservative in the characters we use -- largely limited by our keyboards.
-
We are not, or shouldn't be so conservative in the use we make of those characters.
3. Mathematics Isn't Just Arithmetic
Early uses of computers was primarily in numeric applications. Early precedents for assigning keyboard characters to operators were largely about numerical operators. Which is why "*" for multiplication doesn't seem strange to most of us: it's an early adaptation. It just seems strange to those of us who learned mathematics before they encountered computers.
Mathematics is about formalizing the relationships within any set of values. Operators express those relationships. Mathematicians regularly reused familiar operators, usually based on the idea of analogy: if, an operation establishes a seemingly similar relationship between values as another operation in another mathematical system, then the symbol for that other operation can be borrowed. "+" and "x" (multiplication) are used all over the place, because their analogues are the most commonly occurring operations.
Likewise, legitimate reuse of arithmetic and boolean operations in programming languages is best based on analogy, especially when the reuse is in a part of the language that can be described in formal terms, such as string operations and pattern matching. Which is why Python's use of "+" for string and list concatenation is not so far off the mark. (Although concatenation is, from a mathematical point of view, more closely analogous to multiplication than to addition.)
The days of computers as "number crunchers" is over. Today computers are primarily text processing machines. So it is natural for the "arithmetic" of pattern matching and of string processing to be something we have (or reuse) operators for. It's best done by analogy, of course, as I've attempted in my Python pattern matching sublanguage ("&" for "and", "-" for "but not"). But sometimes you've just got to do an aleph and use what's available (as in my use of "^" for "matches").
4. The Use Of Operator Overloading
The mechanism in programming languages that permits an operator name to be used for more than one purpose is called operator overloading. Many programming languages have this capability, but in a restricted form, like Python.
The most obvious use of operator overloading is to allow things like "+" to apply to different numerical types. But that's the numerical bias. It can also be applied to lots of other possibilities.
But what we need ideally is a more flexible approach to using defining new operators: constructing multi-character symbols (as is commonly done with "<=") and using names (as is done with "and" and "or" in Python).
5. Program Code As Markup
In the early days of programming languages, programmers were familiar with traditional mathematical and scientific texts, with their rich set of mathematical characters, and were well aware of the limitations of keyboard character set available to them on their computers. In the '50's and '60's the situation was even worse than it is now: most keyboards had only uppercase letters, no lowercase, and fewer punctuation characters than now.
In those early days, programmers tended to think of what they typed as a transliteration of the programming language they were using. What they typed was not the "program", but rather an encoding of the program. When properly formatted, the encoding would display what they thought of as the program. The specification of the Algol 60 programming language used boldface type for keywords and single-character operators such as 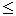 , even though there was no way to directly enter such text. The Algol 68 language had a variety of different input encodings, each appropriate to a different input device.
, even though there was no way to directly enter such text. The Algol 68 language had a variety of different input encodings, each appropriate to a different input device.
The distinction between the input encoding and the display form (for which read "print" in the '60's) is the same as the current distinction between marked-up data and its presentation/formatted form -- the difference between HTML and what we see on the screen in a web browser. Because the practitioners of the time were familiar with the printed form of mathematical-like information, this distinction came naturally to them, just as the familiarity of tagged markup these days makes the HTML/XML vs. presentation form distinction relatively easy to understand to present-day programmers.
All this changed as more and more non-mathematical programmers entered the trade in the '70's and '80's. The educational background of programmers widened considerably, so that no longer could programming language designers make assumptions about how programmers thought about what they were typing. As well, formatting and printing using mathematical fonts was very expensive -- well beyond the means of even university departments. The result was a "one size fits all" a.k.a. "lowest common" approach to representing programming languages. This is the current state of things.
In parallel to the changes in the programming trade, keyboards improved in the '60's and '70's, but in the early '80's they settled down to what we now have under our fingers. Commonly used keyboards are largely unchanged in the last 20 years, at least character-set-wise -- there are more functional keys, but no more characters. Many early character sets were based on six-bit (64 set) encoding, which then expanded to seven-bit encoding, which is what our keyboards are now based on (95 characters plus a variety of control characters).
The current state of affairs is based largely on the computer environment of the '70's and '80's, but things have changed. For example, sophisticated formatting, with large character sets, is inexpensive and relatively easy. What's still not easy is entering other than our 95 characters -- programmers need to easily enter symbols if they are to be expected to use them.
Another unfortunate "one size fits all" a.k.a. "lowest common" parallel is that the markup language community seems to have forgotten the role of XML as a data encoding language -- simple to transmit, to encode and to decode, but designed for computer rather than for human use. Many programmers program directly in XML (XSLT, for example). There are reasons for this, including the fact that "main stream" programming languages don't provide good tools for implementing programming and specification languages. But the primary reason seems to be that the community is disperse enough that representations need to be kept as invariant as possible.
6. Progress Requires That We Accept Change
We've a long history of being flexible in our use of written symbols, and a short history of being overly conservative in our acceptance of new uses for the symbols/characters we use. If progress is to be made in making programming languages more people-friendly we have to come to think of "doing math" with text and pattern matching as natural as with numbers.
Although it may not seem so to those who have entered the field in the last 20 years, we're still very much in the early days of the development of programming languages, but we've already forgot a lot of our short history. Obsessing about the past isn't going to get us very far, but we need to understand our past to be able to move into the future.
We also need help from our programming language designers and software developers:
-
more flexible overloaded operator capabilities,
-
simple ways of using a larger character set (software can help a lot, but hardware-supported standardized key cap assignment also helps).
And I want to be able to show programmers new uses of symbolic or named operators without their first reaction being "perversion".
© copyright 2004 by Sam Wilmott, All Rights Reserved
Sat Jul 03 16:27:58 2004